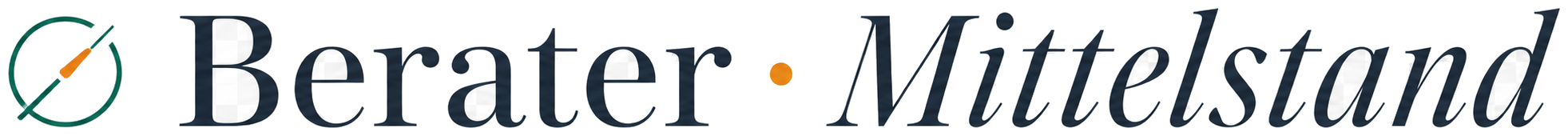

Die Schatten-KI-Welle
Die produktivste Mitarbeitergruppe in vielen deutschen Mittelständlern ist im Jahr 2026 die der heimlichen ChatGPT-Nutzer. Sie kopieren Vertragsentwürfe in den Browser, lassen Kunden-E-Mails formulieren, befragen das Modell zu internen Spezifikationen — und glauben, dass das niemand merkt. Sie haben halb recht: ihre Geschäftsleitung sieht es nicht. Der Anbieter ihres Modells aber schon.
Branchenbeobachtungen aus dem laufenden Jahr deuten darauf hin, dass die unkontrollierte Nutzung von ChatGPT, Claude, Gemini oder vergleichbaren Tools ohne explizite Genehmigung in deutschen Mittelständlern weit verbreitet ist — vielerorts ist sie eher Normalfall als Ausnahme. Diese Schatten-KI ist nicht nur ein Compliance-Risiko, sondern ein Wettbewerbsnachteil: das Wissen, das aus den eingegebenen Daten entsteht, gehört dann faktisch dem Anbieter des Modells.
Das Compliance-Problem: Was passiert mit Ihren Daten?
Die Allgemeinen Geschäftsbedingungen der gängigen Anbieter sind über die Jahre transparenter geworden — die juristischen Implikationen für deutsche Unternehmen aber nicht weniger problematisch:
- Datenverarbeitung außerhalb der EU. OpenAI, Anthropic und Google verarbeiten Anfragen größtenteils in den USA. Das macht jeden Prompt zu einem internationalen Datentransfer mit dokumentationspflichtigen Konsequenzen nach DSGVO und Cloud Act.
- Mögliche Trainingsnutzung. Auch wenn führende Anbieter inzwischen „Opt-out" für die Trainingsnutzung anbieten — die De-facto-Beweislast liegt beim Kunden. Wer einen vertraulichen Geschäftstext in eine Anfrage stellt, kann später nicht zweifelsfrei nachweisen, dass dieser Text nicht in zukünftigen Modellversionen auftaucht.
- Keine Auftragsverarbeitung nach Art. 28 DSGVO. Standard-API-Verträge der Hyperscaler sind in der Regel keine vollwertigen AV-Verträge. Die juristischen Anforderungen werden nur teilweise erfüllt.
- Wettbewerbssensible Daten. Selbst wenn rechtlich alles in Ordnung wäre: jeder Prompt, der eine eigene Roadmap, einen Kundenstamm oder eine Kalkulationsgrundlage offenbart, ist ein potenzieller Wettbewerbsverlust.
Drei KI-Use-Cases, die im Mittelstand wirklich tragen
Trotz dieser Risiken ist es keine Lösung, KI im Unternehmen verbieten zu wollen — die Mitarbeiter nutzen sie ohnehin, nur eben unbeobachtet. Sinnvoller ist die Frage, welche KI-Anwendungen sich mit kontrollierter Infrastruktur lohnen. Drei Use-Cases haben sich in der mittelständischen Praxis als tragfähig erwiesen:
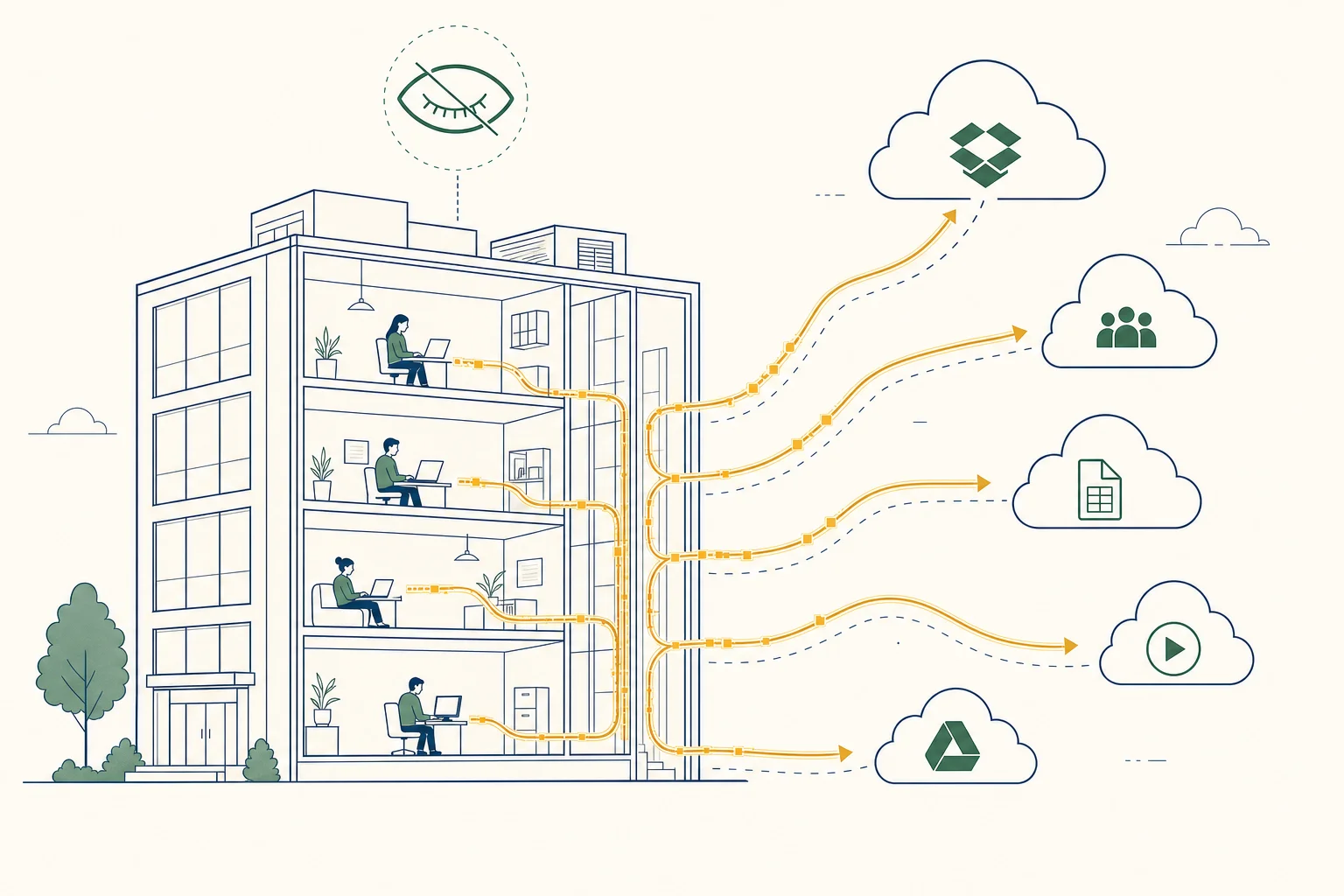
1. RAG: Sprachmodelle auf eigenen Dokumenten
„Retrieval-Augmented Generation" verbindet ein vortrainiertes Sprachmodell mit einer Datenbank eigener Dokumente. Eine Anfrage wird zunächst gegen die eigene Wissensbasis recherchiert; nur die relevanten Ausschnitte werden dann gemeinsam mit der Frage an das Modell übergeben. Das Modell antwortet auf Basis der zitierten Quellen — und liefert dabei die Fundstellen mit. So lassen sich technische Dokumentationen, Verträge, Compliance-Vorgaben oder ganze Wissensbasen abfragbar machen, ohne dass das Modell selbst die Inhalte „lernen" muss.
2. Strukturierung von Freitext
Vielleicht der unscheinbarste, aber zeitlich wertvollste Use-Case: aus unstrukturierten Eingaben — Bestell-E-Mails, Kundenrückmeldungen, Reklamationen, Polizeiberichten — werden über ein Sprachmodell strukturierte Daten extrahiert. Output-Schemata sind frei konfigurierbar, die Verarbeitung lässt sich batchen, das Modell muss die Inhalte nicht „verstehen", sondern nur formal extrahieren. Aus einer Stunde manueller Datenpflege werden so wenige Sekunden Verarbeitung.
3. Wissensmanagement mit KI-Unterstützung
Die schlankste Form intelligenter Wissensbasis: Mitarbeiter dokumentieren in natürlicher Sprache; das Sprachmodell hilft bei Strukturierung, Verschlagwortung und beim Auffinden ähnlicher Einträge. Suchanfragen funktionieren auch ohne exakte Begriffsübereinstimmung. Wer als Mittelständler heute noch ein Confluence-Wiki ohne KI-Unterstützung pflegt, hinkt diesem Standard zunehmend hinterher.
Was nicht zum Use-Case taugt
Vorsichtig sollte man bei drei Versuchungen sein: autonome Agenten, die ohne menschliche Freigabe Aktionen auslösen (Mailversand, Vertragsabschluss) — Compliance-Risiko zu hoch; Text-Generierung als Kern einer Geschäftsleistung — rechtlich grenzwertig, qualitativ unzuverlässig; Vorhersagemodelle ohne Erklärbarkeit — die meisten Mittelständler haben weder die Datenbasis noch das ML-Ops-Know-how für echte Predictive-Use-Cases.
Was ein konformer KI-Stack braucht
Wer KI im Mittelstand tatsächlich nutzen will, ohne in Schatten-IT zu verfallen, sollte vier Eigenschaften aktiv suchen:
- Modell-Proxy mit eigener Kontrolle. Anstatt jedem Mitarbeiter einen eigenen OpenAI-Account zu geben, wird ein zentraler Proxy etabliert. Anfragen lassen sich protokollieren, anonymisieren, mit Berechtigungen versehen und auf konkrete Use-Cases beschränken.
- RAG-Pipeline auf eigenen Daten. Embedding-Datenbank im eigenen Rechenzentrum oder einer DE/EU-Cloud, Quellen-Nachweis in jeder Antwort, klare Berechtigungsmodelle pro Dokument.
- Wahl des Modells und Anbieters. Nicht jedes Use-Case braucht GPT-4o. Manche Aufgaben (Strukturierung, Klassifikation) lassen sich mit kleineren, in der EU gehosteten Modellen wirtschaftlicher und rechtssicherer abdecken.
- Audit-Trail und Kostentransparenz. Wer wann welche Anfrage gestellt hat, mit welchem Modell, zu welchen Kosten — diese Sicht braucht jede Geschäftsleitung, die KI im Unternehmen nicht nur „erlauben", sondern strategisch steuern will.
Anbieter im Fokus: KI-Bausteine aus dem ProcessHub
Eine im deutschen Mittelstand etablierte Plattform, die diese vier Eigenschaften out-of-the-box liefert, ist ProcessHub der CamData GmbH. Die KI-Bausteine sind als Module aufgebaut: Modell-Proxy mit zentraler Konfiguration, RAG-Pipeline auf eigenen Dokumenten (Demo: Grundgesetz-RAG), Freitext-Strukturierung, KI-gestütztes Wissensmanagement.
Worauf bei der Auswahl zu achten ist
Eine kurze Checkliste für die Bewertung von KI-Lösungen im Mittelstand:
- Wo werden die Daten verarbeitet? EU-Hosting, AV-Vertrag, klare Subunternehmerliste.
- Modell-Auswahl flexibel oder fest? Ein Tool, das nur OpenAI kann, ist abhängig. Ein Proxy mit mehreren Modellen erhält Optionalität.
- Quellen-Nachweis bei RAG? Antworten ohne Fundstellen sind in regulierten Branchen wertlos.
- Audit-Trail? Welche Anfrage wurde wann mit welchem Modell gestellt? Diese Sicht braucht jede Compliance-Funktion.
- Trainingsdaten-Schutz? Explizite vertragliche Zusicherung, dass eigene Daten nicht in Modell-Training fließen.
Fazit
KI im Mittelstand ist 2026 angekommen — die Frage ist allerdings nicht „ob wir mitmachen", sondern „unter welchen Bedingungen". Die unkontrollierte Schatten-Nutzung von ChatGPT & Co produziert Wettbewerbs- und Compliance-Risiken in einem Ausmaß, das vielen Geschäftsleitungen noch nicht klar ist.
Die wirksame Antwort ist nicht ein KI-Verbot, sondern ein kontrollierter Stack: zentraler Modell-Proxy, RAG-Pipeline auf eigenen Daten, klare Modell-Auswahl, lückenloser Audit-Trail. Drei Use-Cases tragen dabei wirklich: RAG, Freitext-Strukturierung und KI-gestütztes Wissensmanagement. Wer hier anfängt, gewinnt Produktivität ohne Datenabfluss — und kann später erweitern, wenn die Use-Cases reifer werden.